Publications (Full List)
Preprint
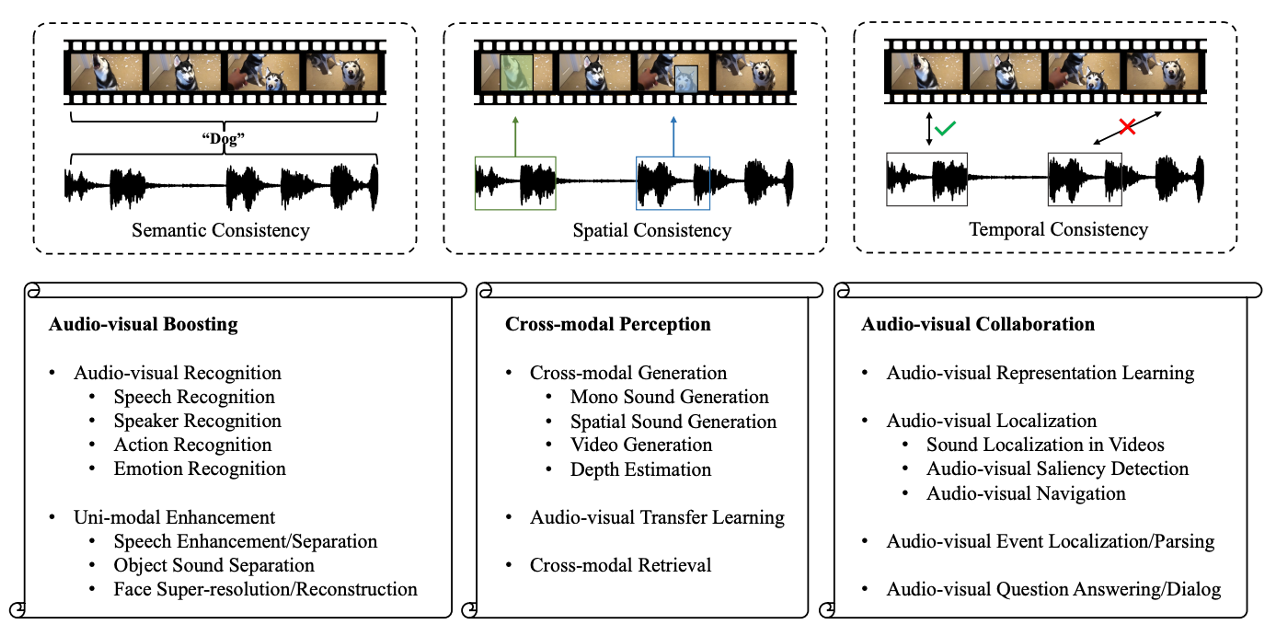 |
Learning in Audio-visual Context: A Review, Analysis, and New Perspective |
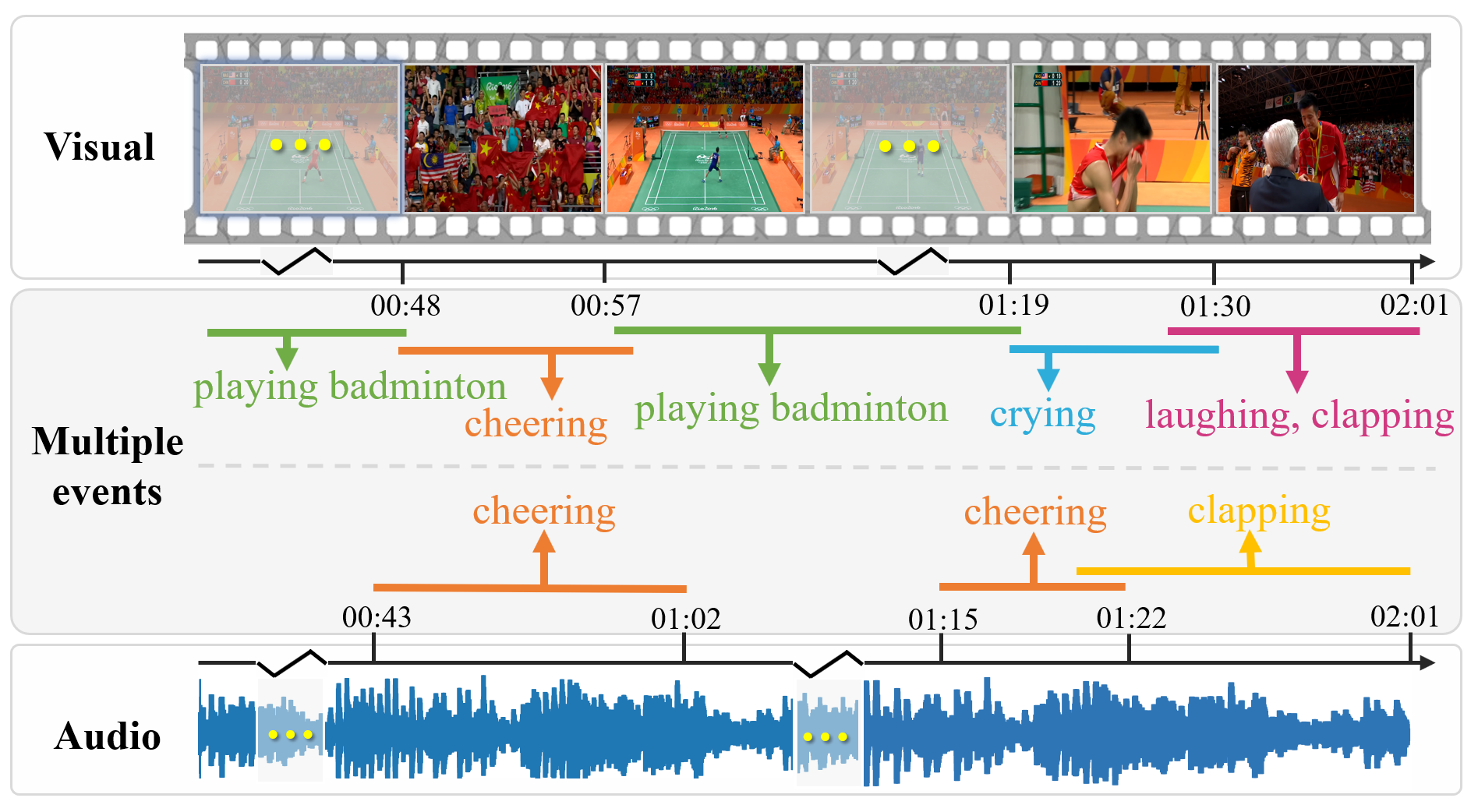 |
Towards Long Form Audio-visual Video Understanding |
 |
Not All Knowledge Is Created Equal |
 |
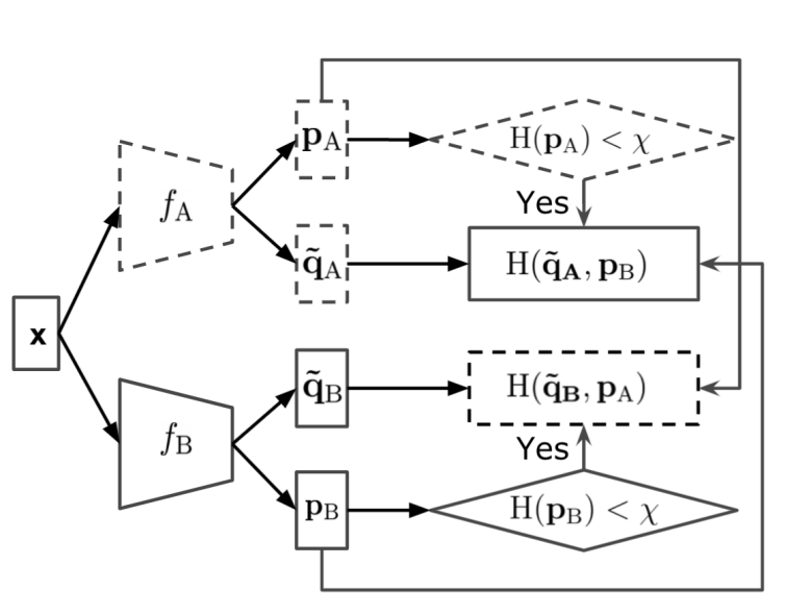
Towards Accurate Knowledge Transfer via Target-awareness Representation Disentanglement |
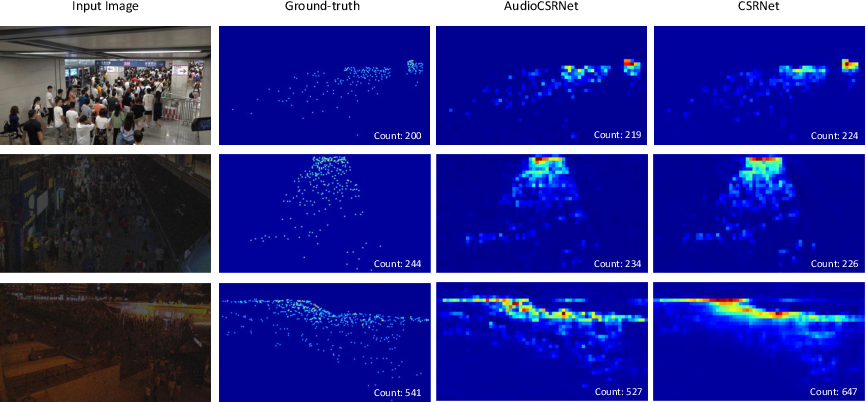 |
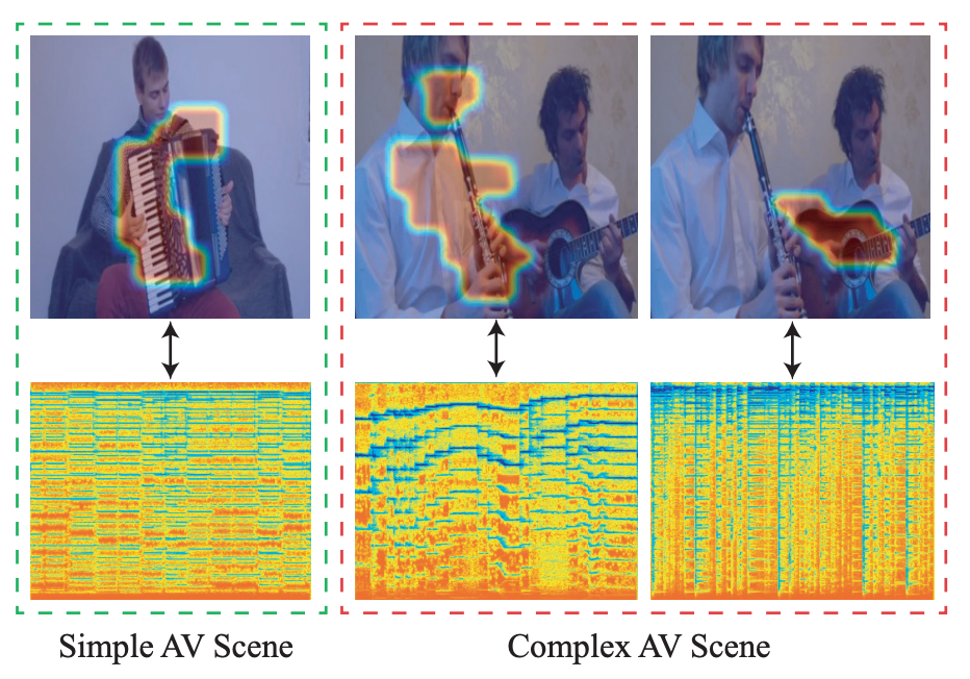
Ambient Sound Helps: Audiovisual Crowd Counting in Extreme Conditions |
 |
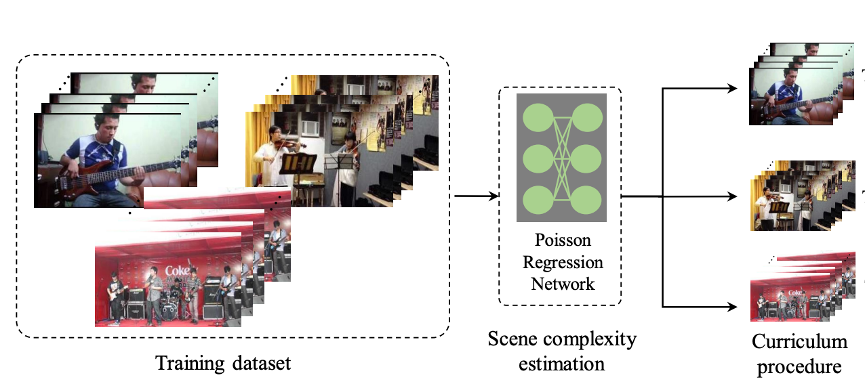
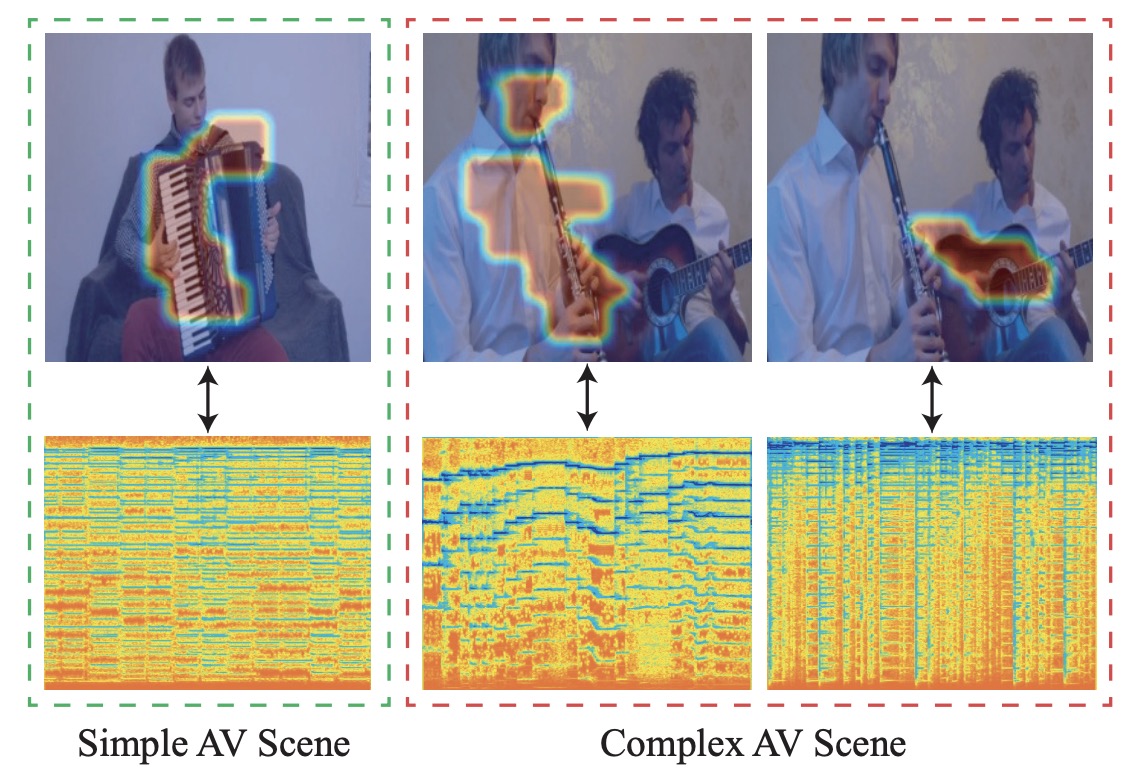
Curriculum Audiovisual Learning |
Conference Papers (Full List)
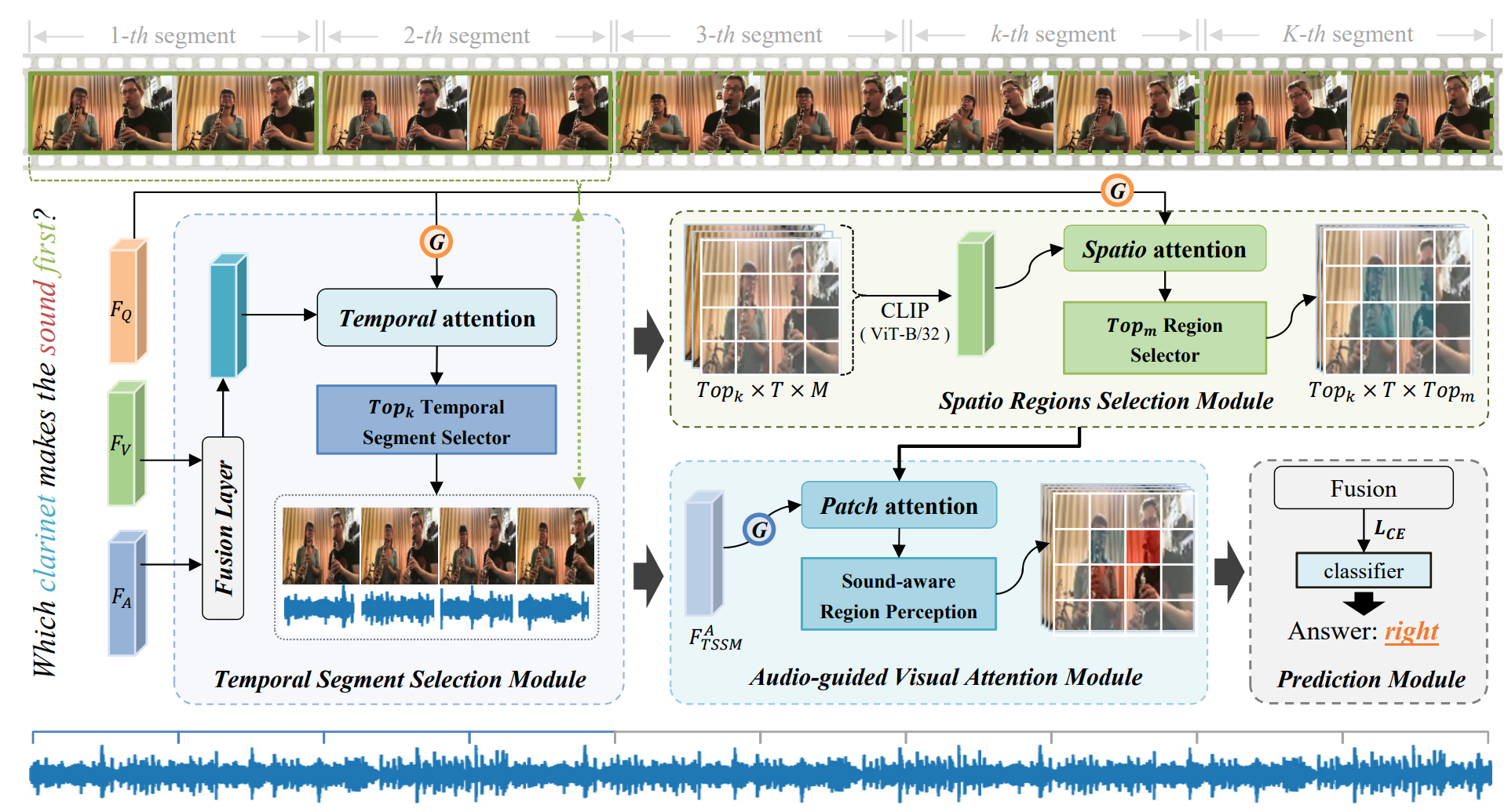 |
Progressive Spatio-temporal Perception for Audio-Visual Question Answering |
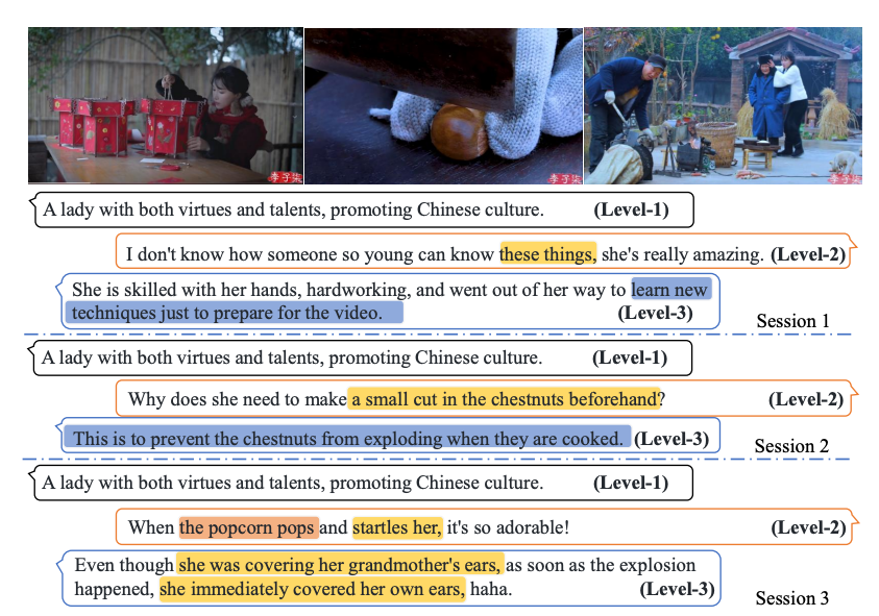 |
TikTalk: A Video-Based Dialogue Dataset for Multi-Modal Chitchat in Real World |
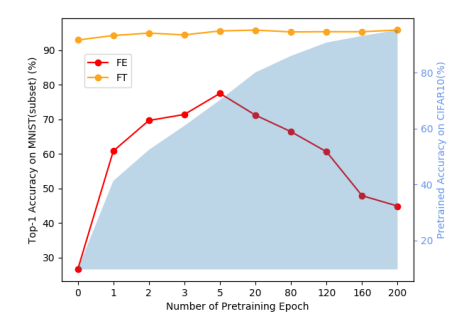 |
Towards Inadequately Pre-trained Models in Transfer Learning |
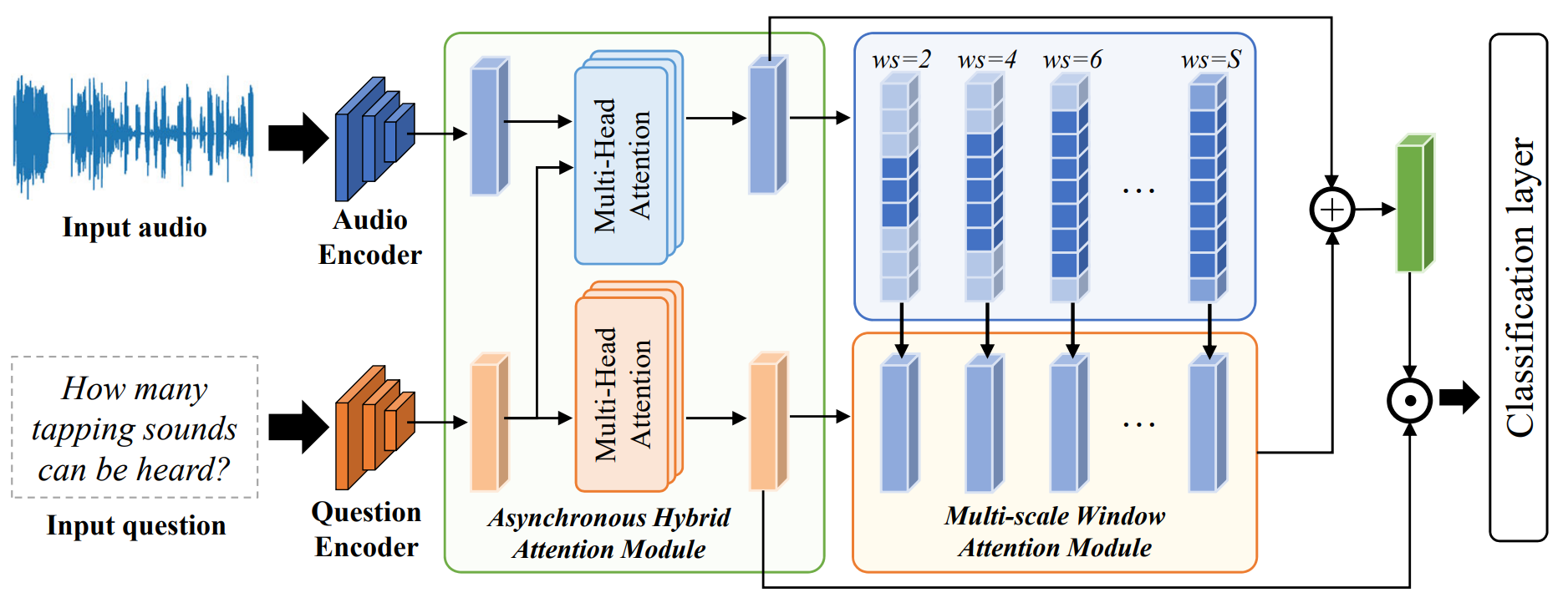 |
Multi-Scale Attention for Audio Question Answering |
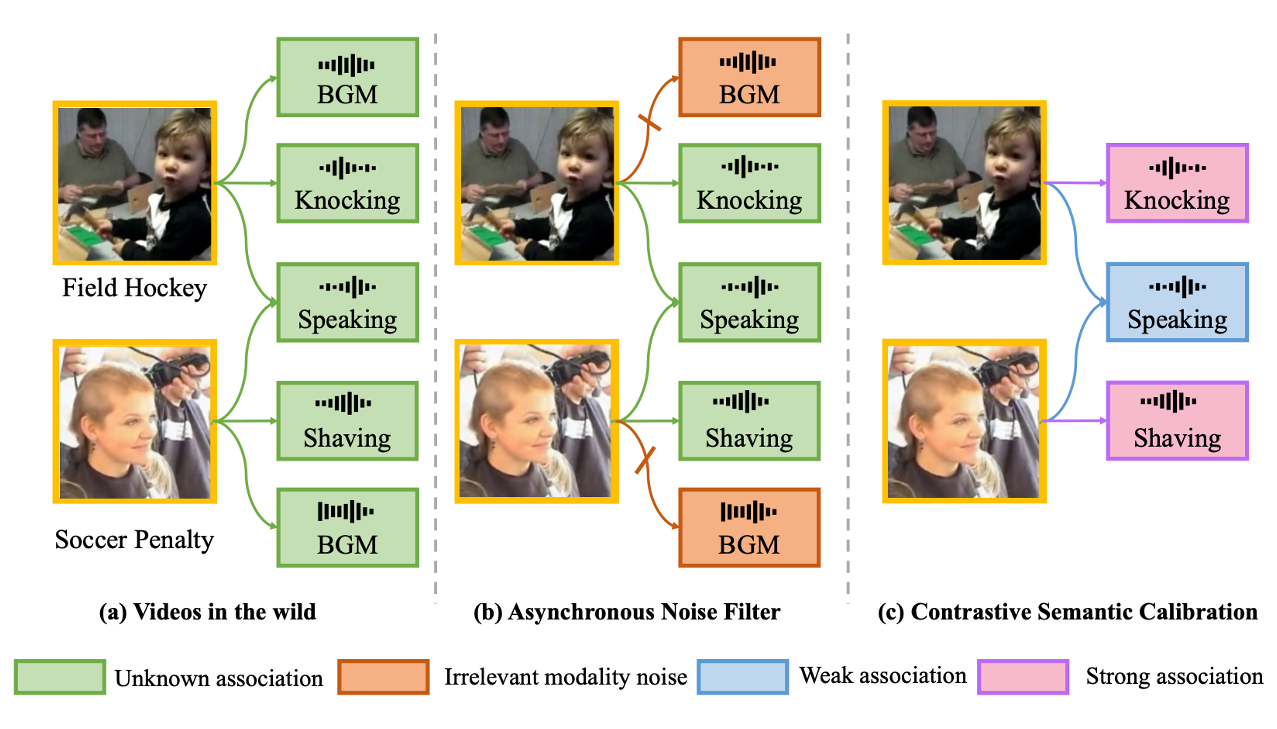 |
Robust Cross-Modal Knowledge Distillation for Unconstrained Videos |
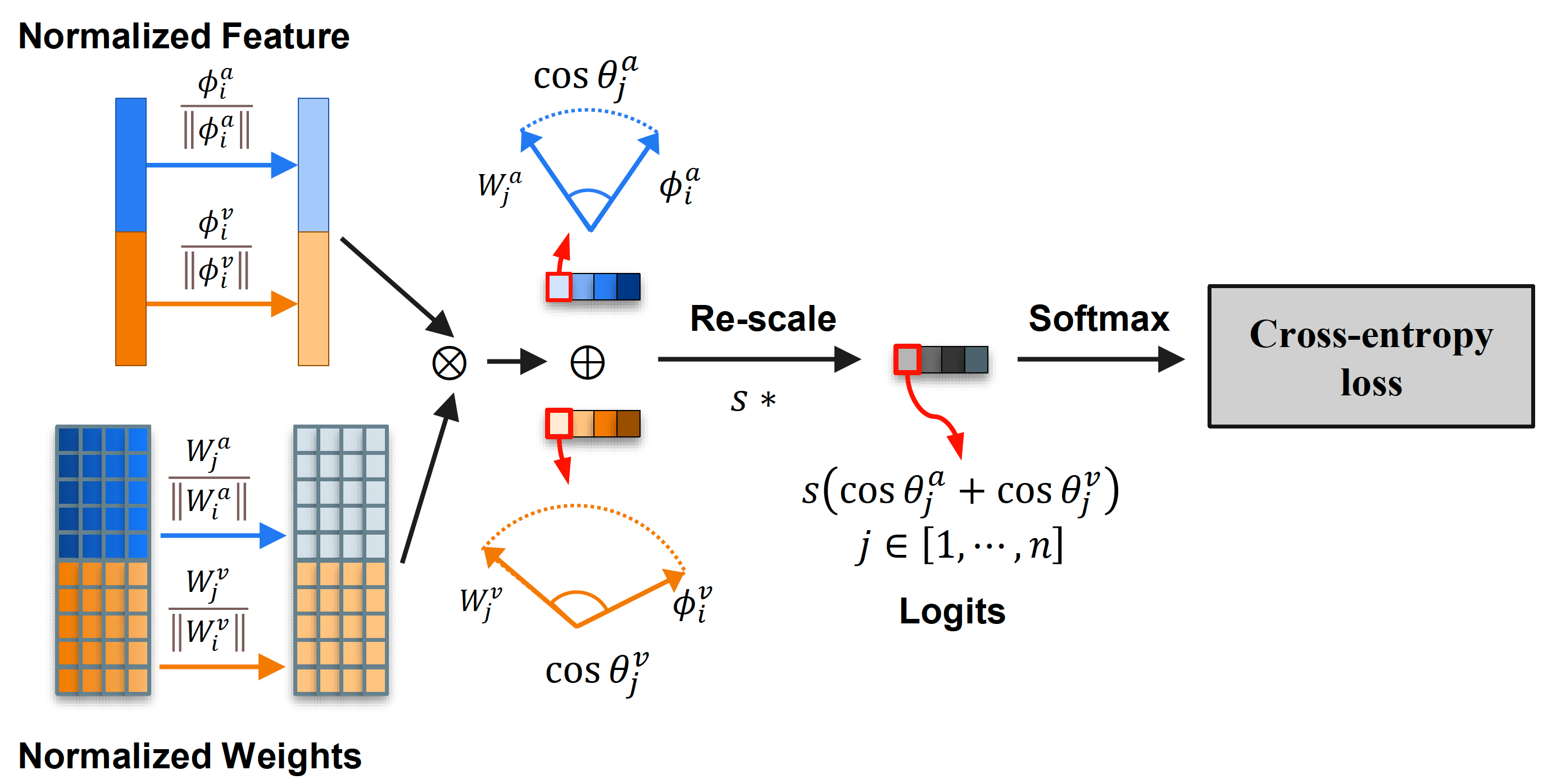 |
MMCosine: Multi-Modal Cosine Loss Towards Balanced Audio-Visual Fine-Grained Learning |
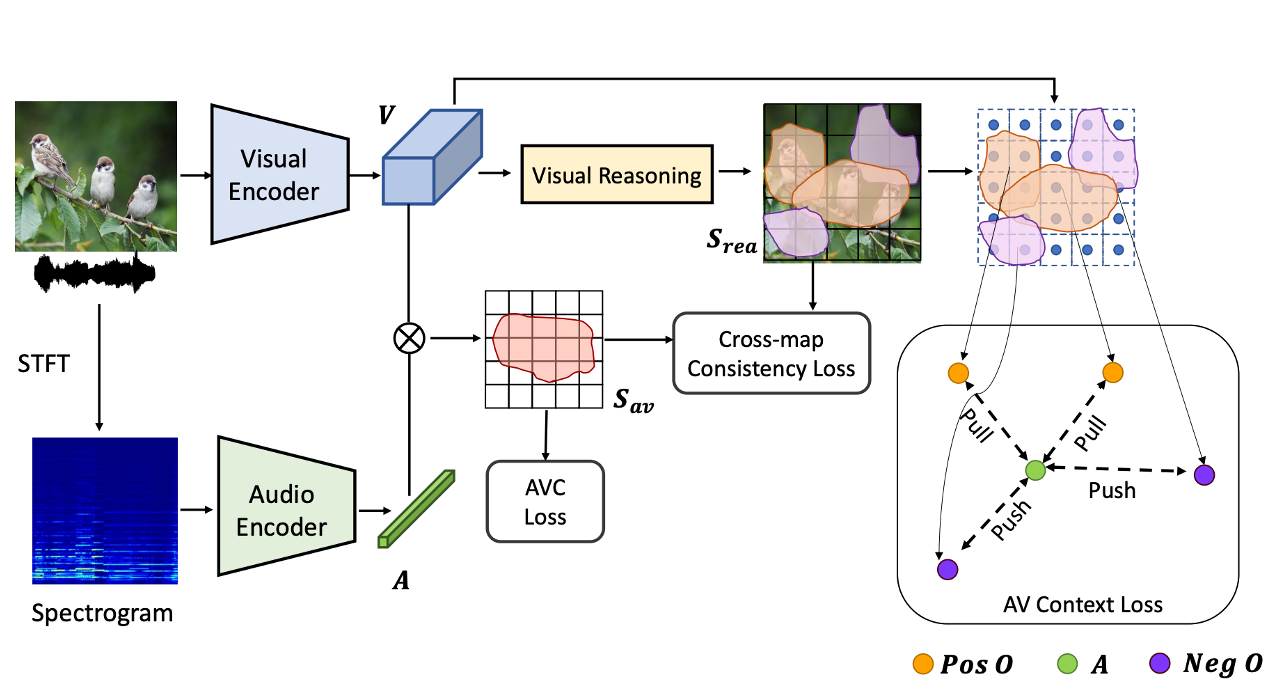 |
Exploiting Visual Context Semantics for Sound Source Localization |
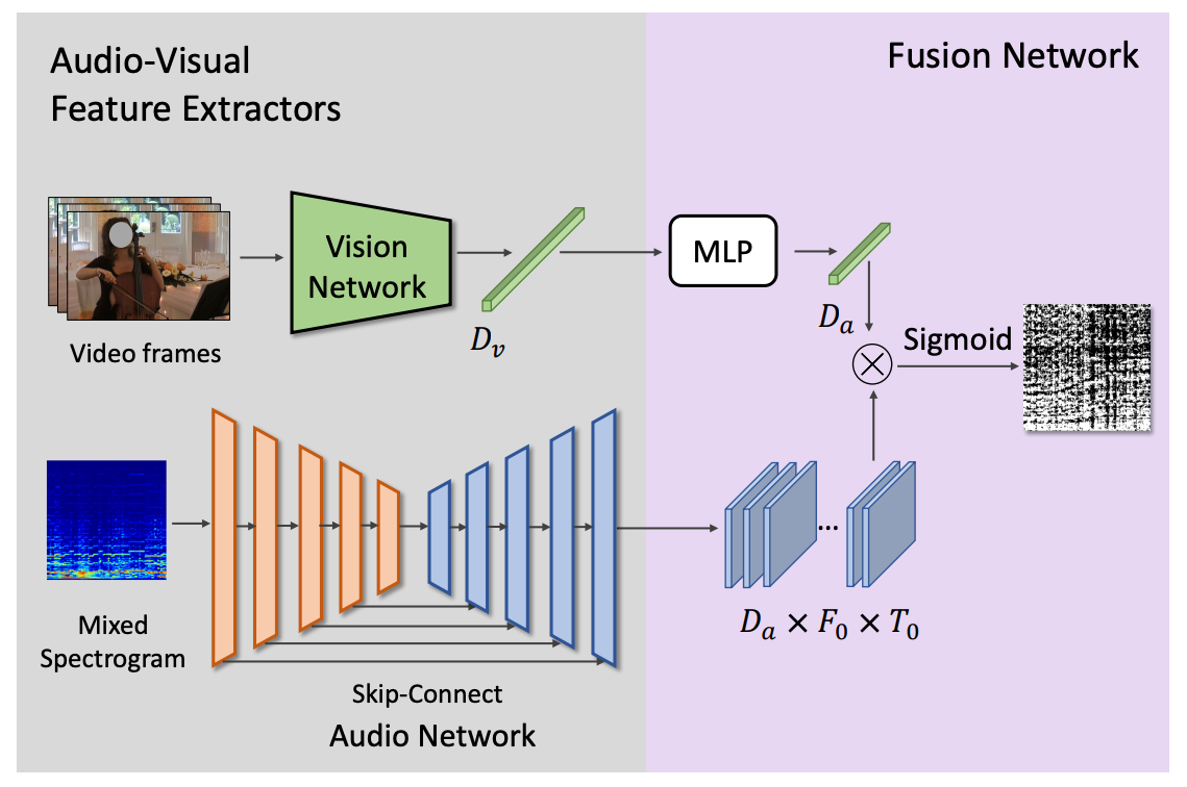 |
SeCo: Separating Unknown Musical Visual Sounds with Consistency Guidance |
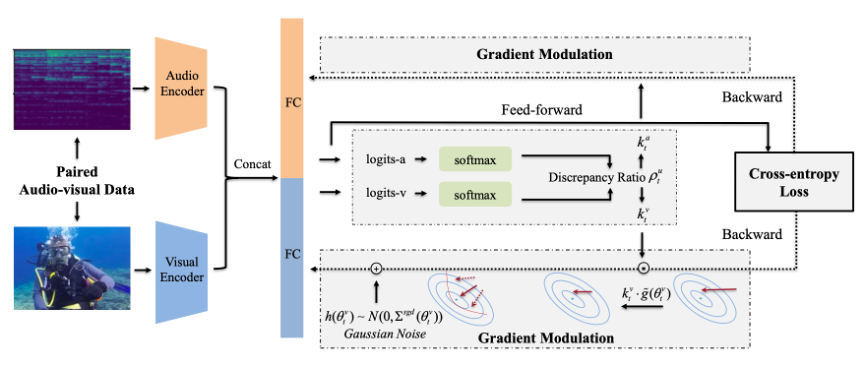 |
Balanced Multimodal Learning via On-the-fly Gradient Modulation |
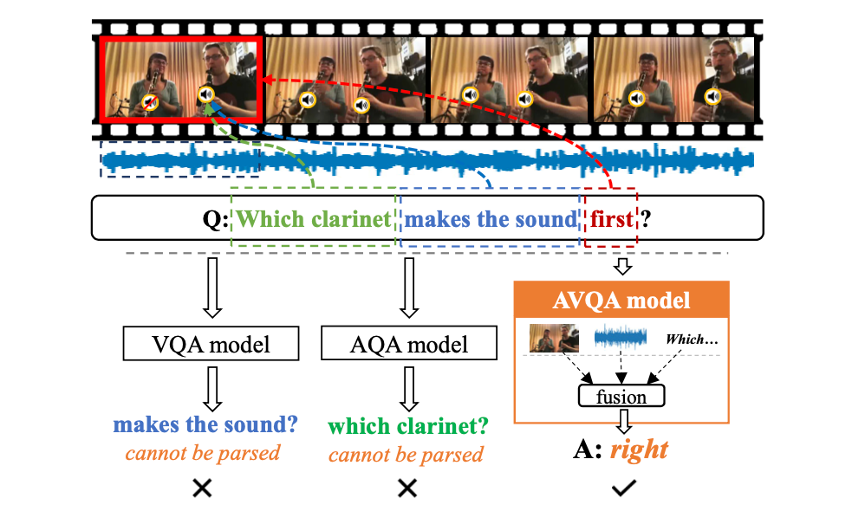 |
Learning to Answer Questions in Dynamic Audio-Visual Scenarios |
 |
Visual Sound Localization in-the-Wild by Cross-Modal Interference Erasing |
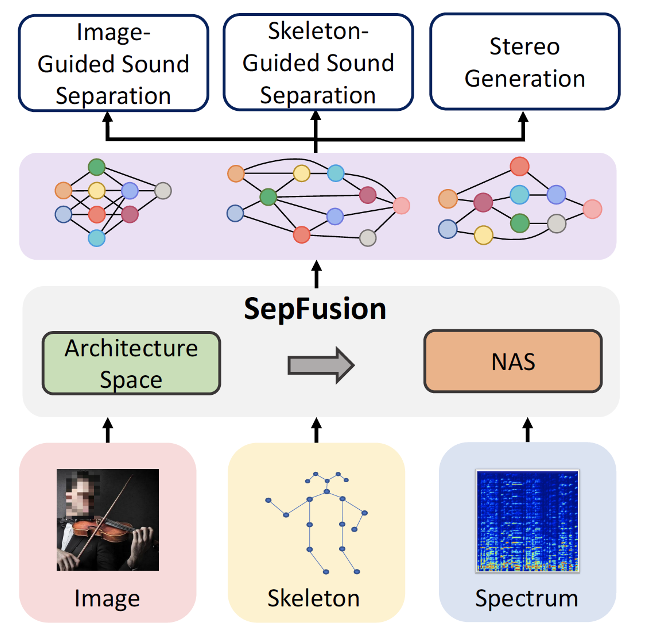 |
SepFusion: Finding Optimal Fusion Structures for Visual Sound Separation |
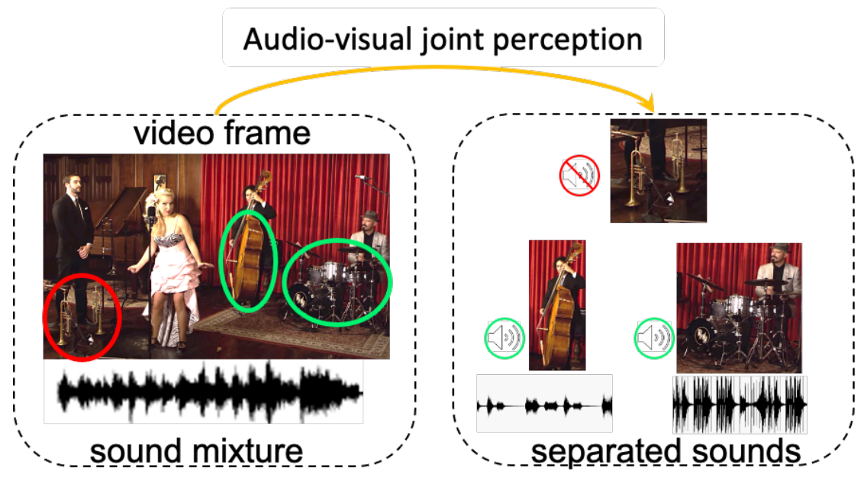 |
Cyclic Co-Learning of Sounding Object Visual Grounding and Sound Separation |
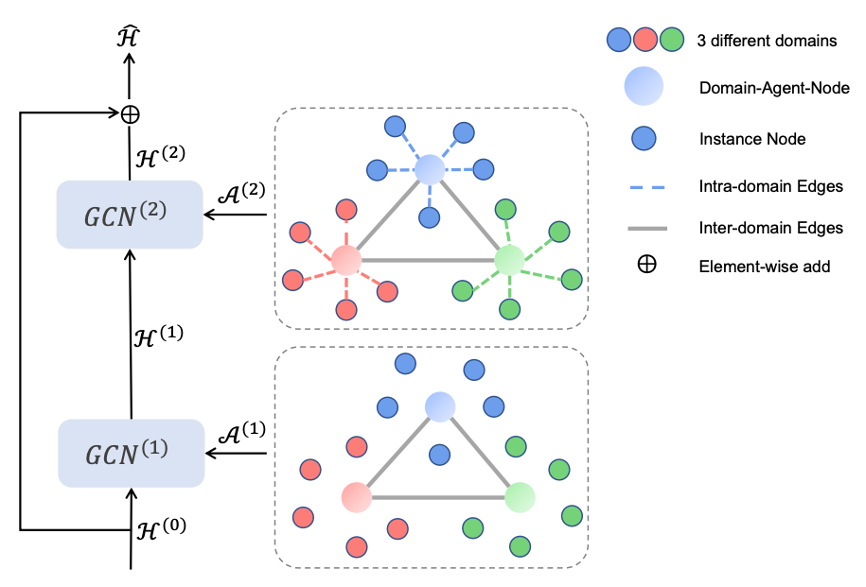 |
Unsupervised Multi-Source Domain Adaptation for Person Re-Identification |
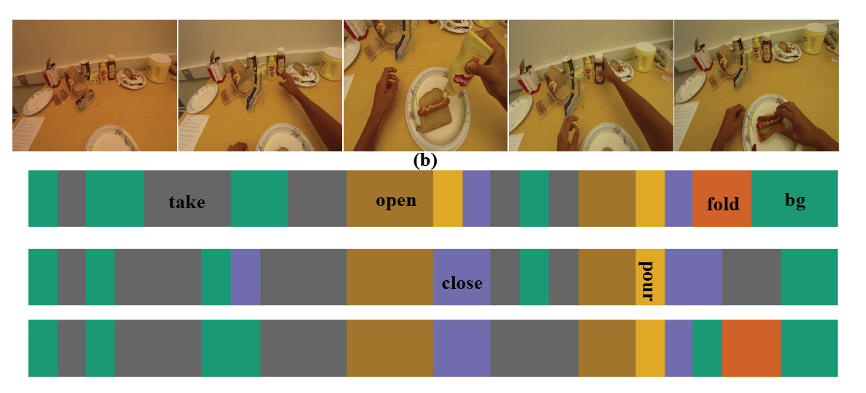 |
Temporal Relational Modeling with Self-Supervision for Action Segmentation |
 |
Discriminative Sounding Objects Localization via Self-supervised Audiovisual Matching |
 |
Cross-Task Transfer for Geotagged Audiovisual Aerial Scene Recognition |
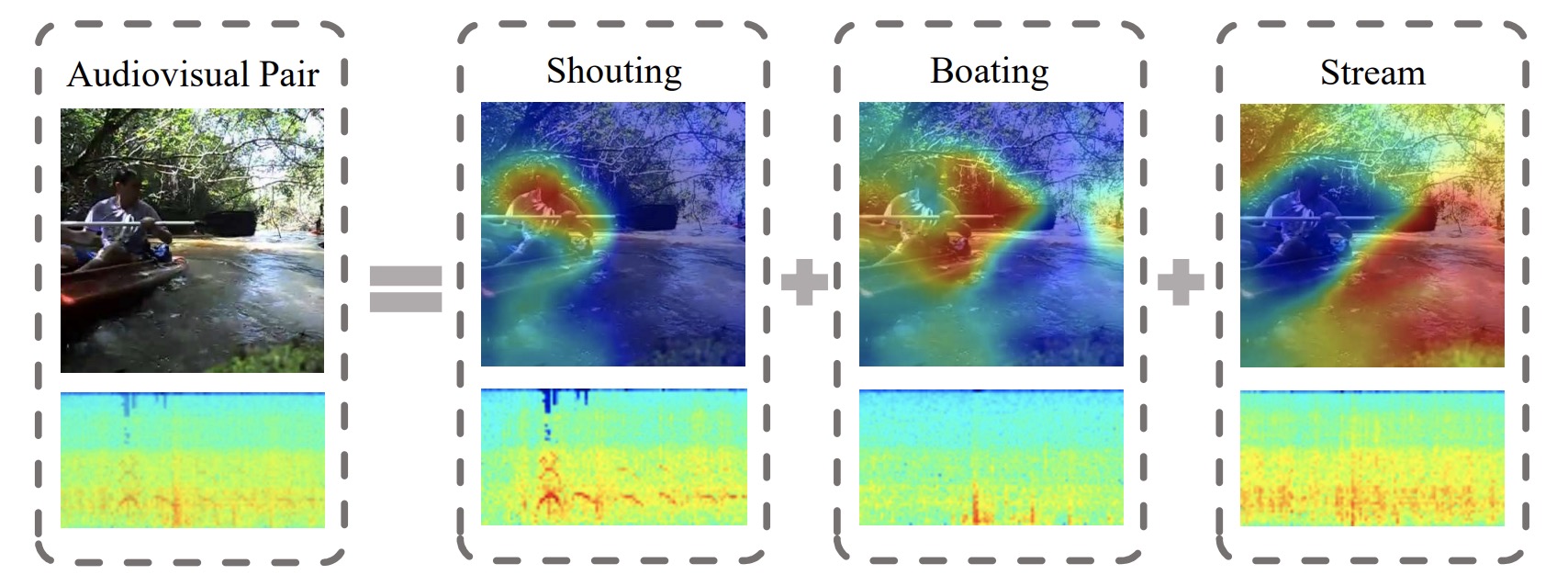 |
Multiple Sound Sources Localization from Coarse to Fine |
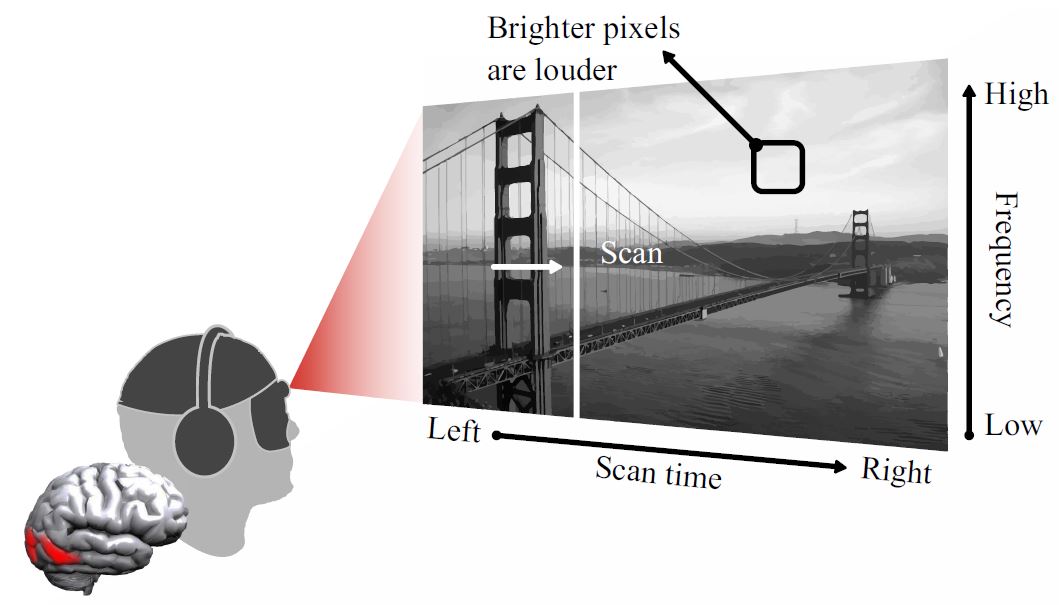 |
Listen to the Image |
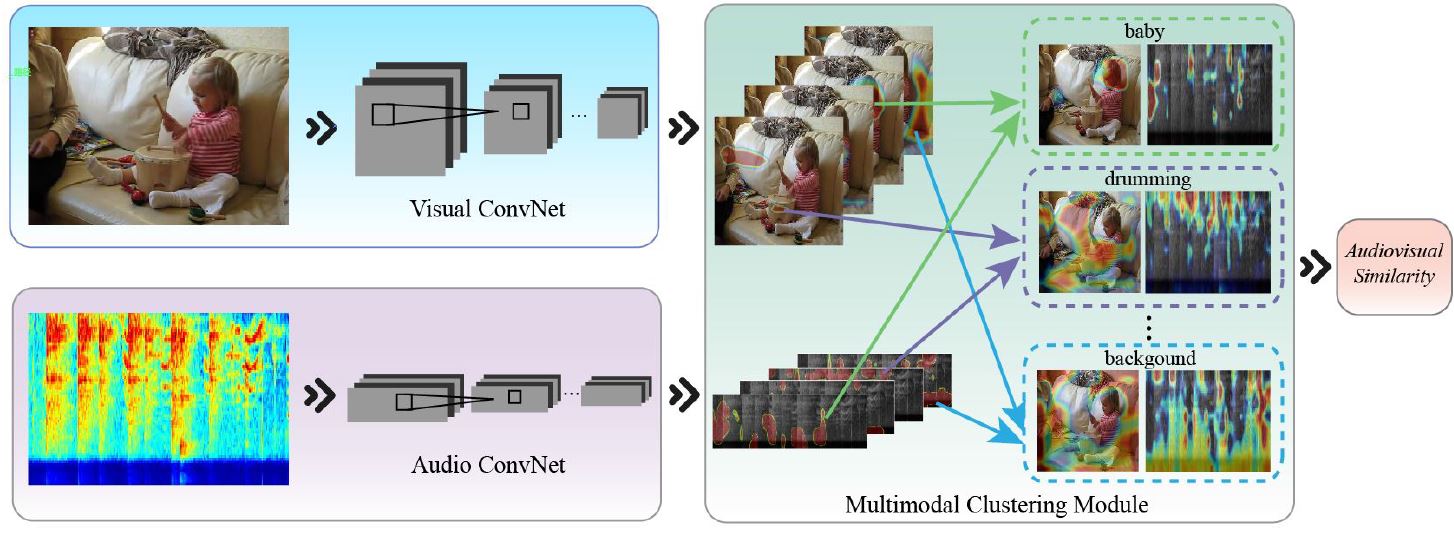 |
Deep Multimodal Clustering for Unsupervised Audiovisual Learning |
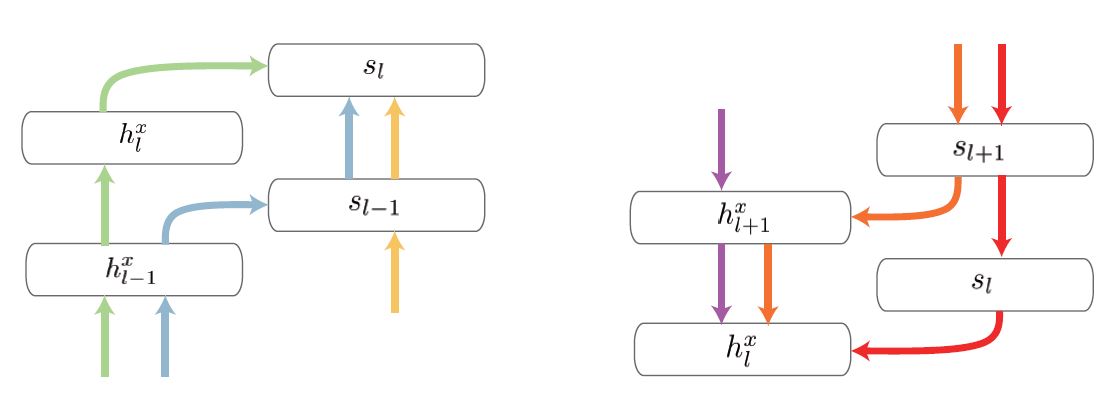 |
Dense Multimodal Fusion for Hierarchically Joint Representation |
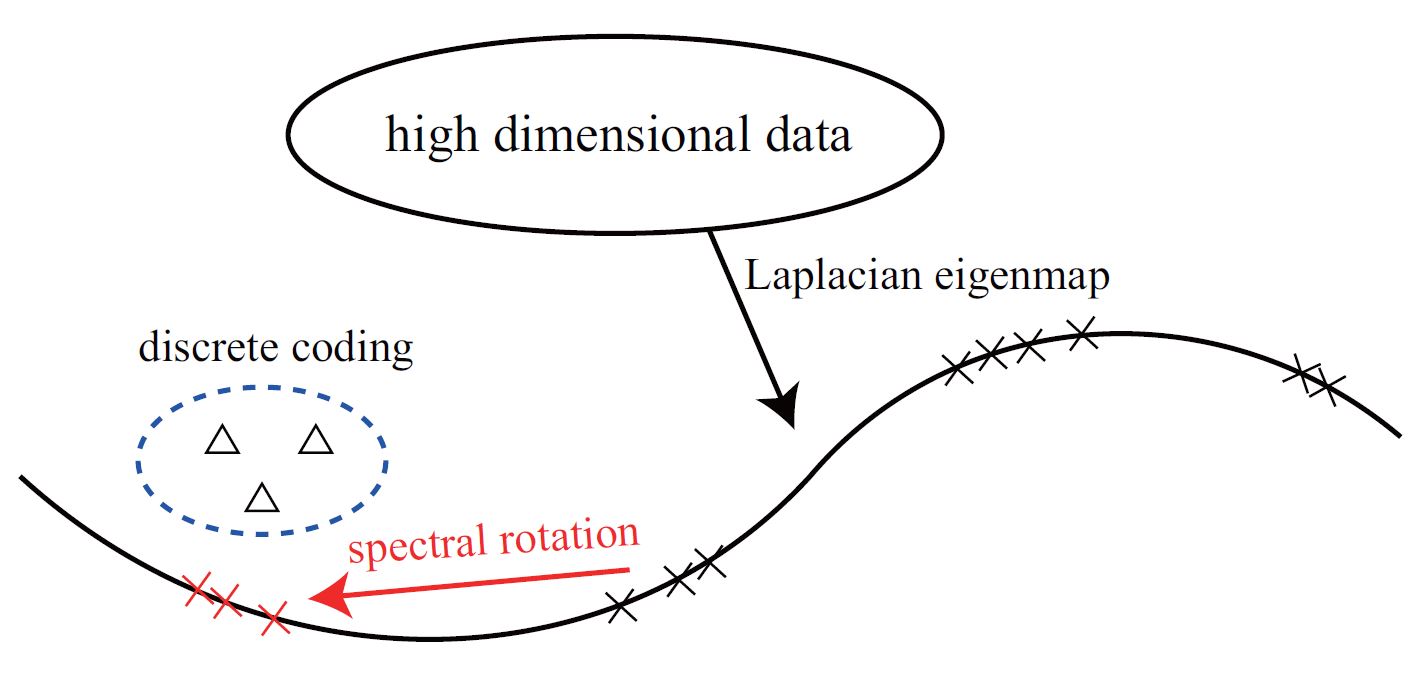 |
Large Graph Hashing with Spectral Rotation |
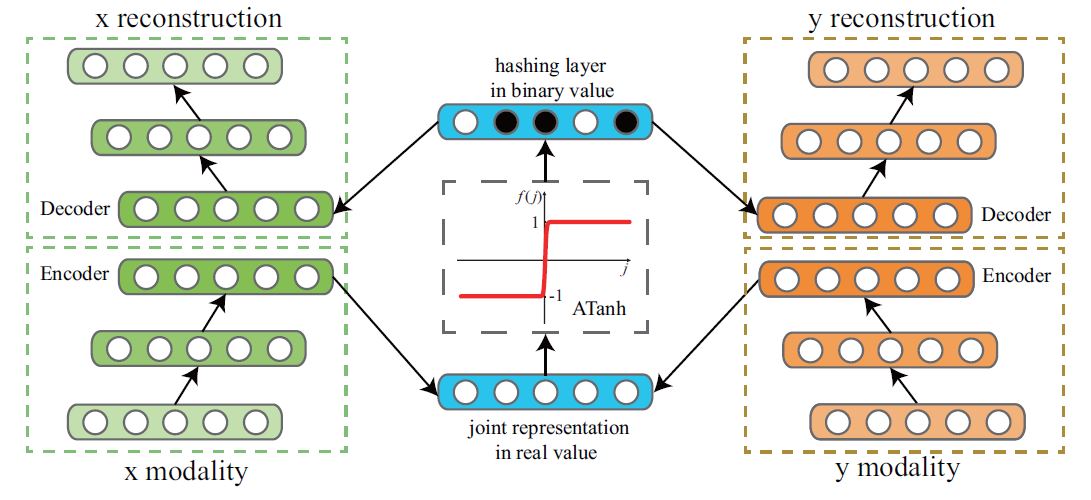 |
Deep Binary Reconstruction for Cross-modal Hashing |
 |
Image2song: Song Retrieval via Bridging Image Content and Lyric Words |
 |
Multimodal Learning via Exploring Deep Semantic Similarity |
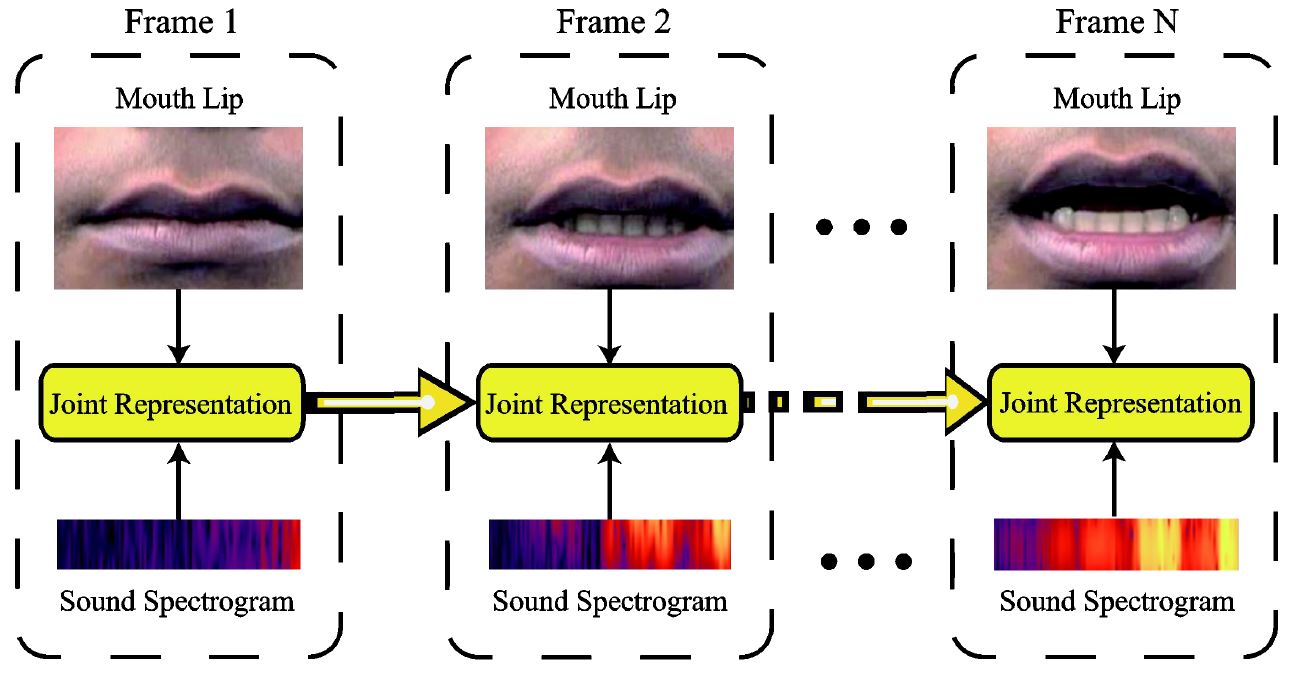 |
Temporal Multimodal Learning in Audiovisual Speech Recognition |
Journal Papers
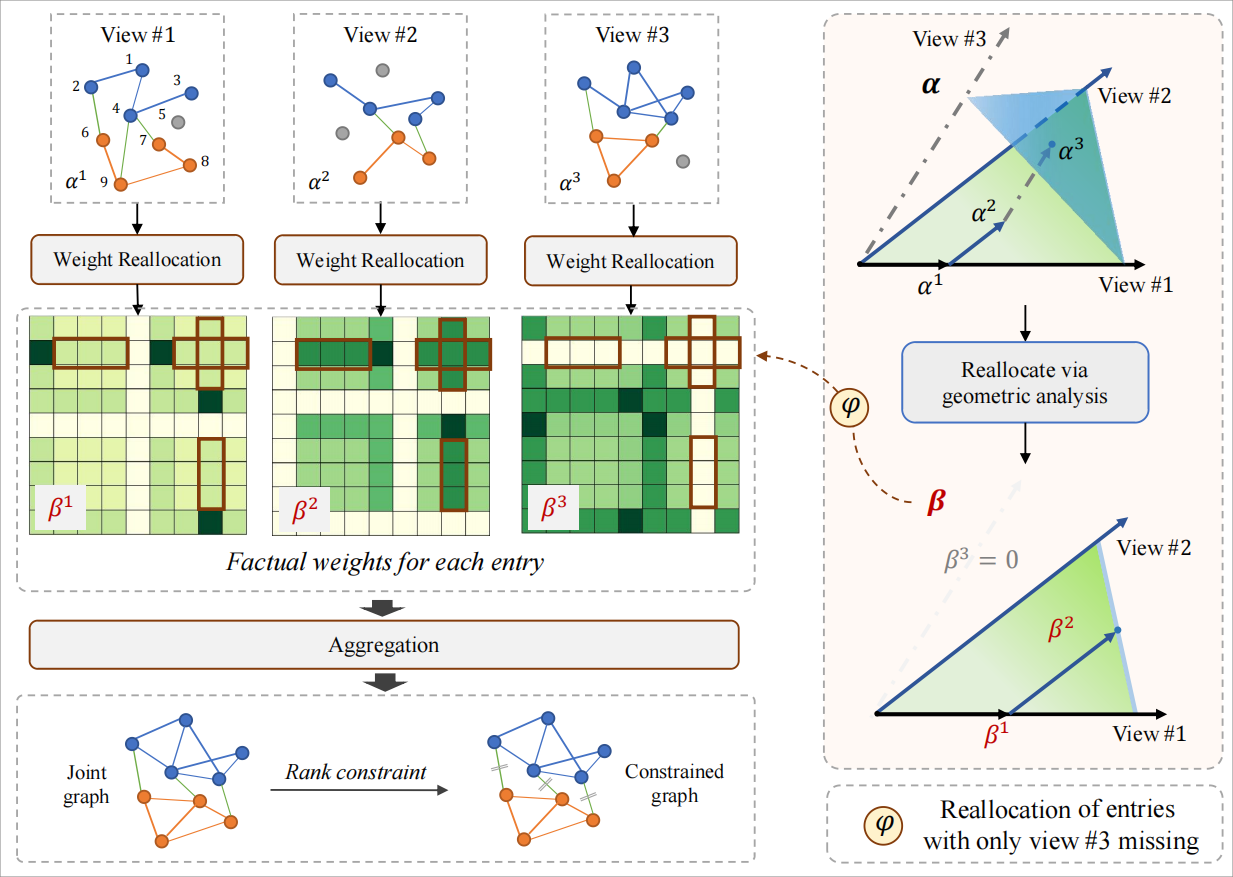 |
Geometric-Inspired Graph-based Incomplete Multi-view Clustering |
 |
Supervised Knowledge May Hurt Novel Class Discovery Performance |
 |
Self-supervised Audiovisual Representation Learning for Remote Sensing Data |
 |
Self-supervised Learning for Heterogeneous Audiovisual Scene Analysis |
 |
Class-aware Sounding Objects Localization via Audiovisual Correspondence |
 |
Generalising Combinatorial Discriminant Analysis through Conditioning Truncated Rayleigh Flow |
|
|
Deep Linear Discriminant Analysis Hashing |
|
|
Discrete Spectral Hashing for Efficient Similarity Retrieval |
|
|
Deep Binary Reconstruction for Cross-modal Hashing |
Workshop Papers
 |
Heterogeneous Scene Analysis via Self-supervised Audiovisual Learning |
 |
Does Ambient Sound Help? - Audiovisual Crowd Counting |
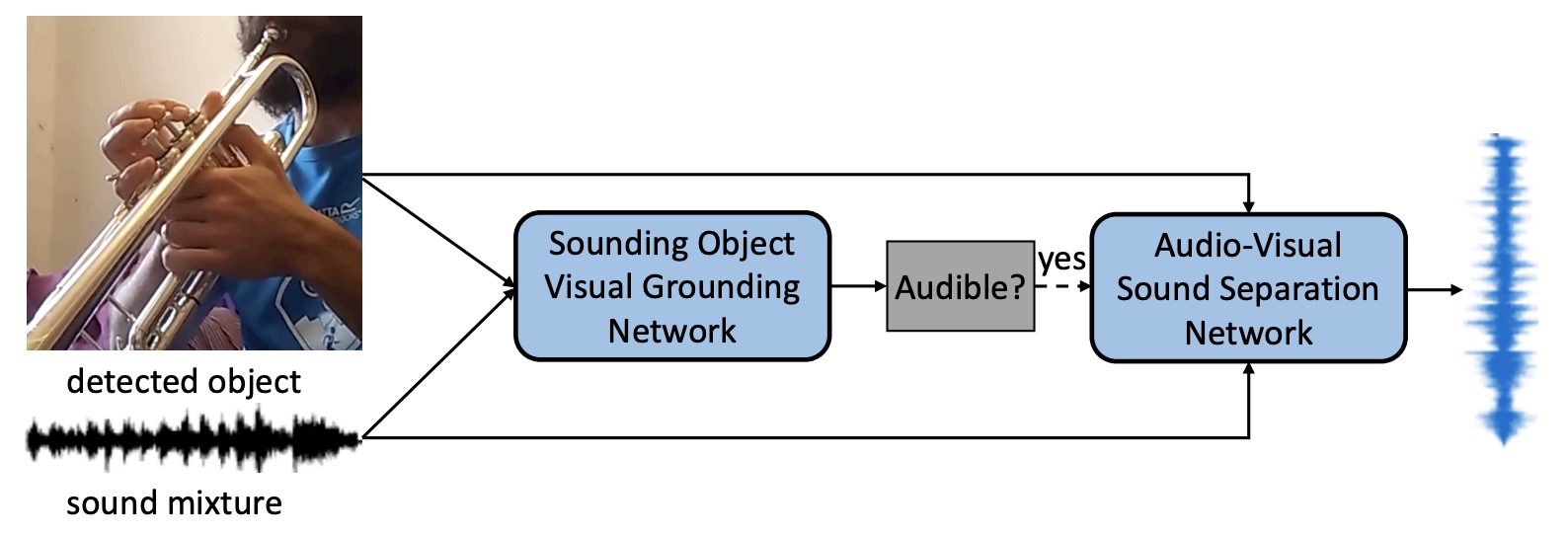 |
Co-Learn Sounding Object Visual Grounding and Visually Indicated Sound Separation in A Cycle |
|
|
A Two-Stage Framework for Multiple Sound-Source Localization |