Projects
Audio-Visual Speaker Diarization
 |
This project is oriented to complex dynamic audio-visual scenes. By mining the context information of long-video sequences, it explores the internal connections of multiple speakers in the spatial and temporal dimensions, proposes a cross-domain matching model to mine the consistent representation of audiovisual modalities, and establishes a dialogue mechanism, finally aiming to improve speaker tracking and diarization performance. |
Sensory Substitution for the Blind
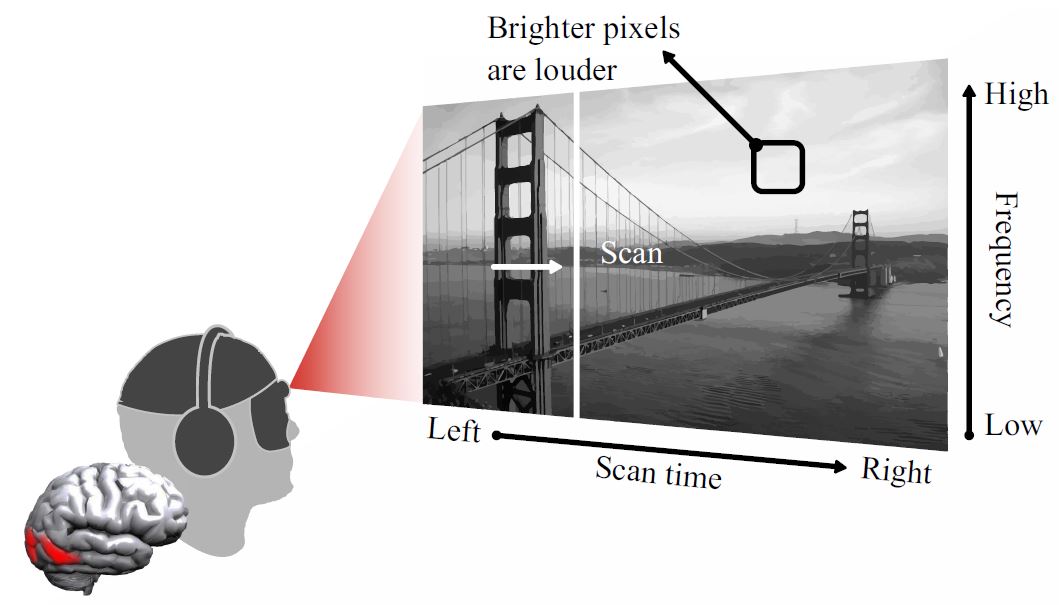 |
GeWu Lab is working on how to develop more effectively cross-modal encoding scheme for the disable people with AI technique. Recently, we have published one paper <Listen to the Image> on the IEEE Computer Vision and Pattern Recognition (CVPR) conference, which employed machine model to automatically evaluate the quality of different V-to-A encoding schemes. This project still has more interesting problems should be explored, e.g. the automatically designed V-to-A encoding Scheme. Not only that, we finally hope we can deploy the devices in China Mainland to help more blind-friends, that is what GeWu Lab really expects! Great thanks for the help from the inventor of the vOICe, Peter Meijer. Recently, we translated the manual of vOICe into Chinese for the training of native Chinese. |
Service Robot
 |
During the undergraduate studies of Prof. Hu, he and his lab-mates developed a home-service robot based on ROS, which is named as XiaoMeng. He mainly focused on the robot configuration and human-computer interface, including face detection, face recognition, and TTS. He also participated in the SLAM work for the robot. And the team won the Second Prize for Home service robot group of RoboCup China Robot Competition in 2013. |
Cognitive Science
 |
GeWu Lab is very curious about the cognition of human, therefore we have ever spent several months studying cognitive science and cognitive psychology. One study note by Prof. Hu can be found here, and some of our works are inspired by them. |