Dataset
MUSIC-Synthetic dataset
 |
We build category-balanced multi-source videos by artificially synthesizing solo videos from the MUSIC dataset to facilitate the learning and evaluation of multiple-soundings-sources localization in the cocktail-party scenario. Concretely, we first randomly choose four 1-second solo audiovisual pairs of different categories, then mix random two of the four audio clips with jittering as the multi-source audio waveform, and concatenate four frames of these clips as the multi-source video frame. That is, in the synthesized audiovisual pairs, there are two instruments making sound while the other two are silent. Therefore, this synthesized dataset is quite proper for the evaluation of discriminatively sounding object localization and we also find it generalizes well in the real-world scenarios. For more details about this dataset, please refer to our paper. Download this dataset here |
AuDio Visual Aerial sceNe reCognition datasEt (ADVANCE)
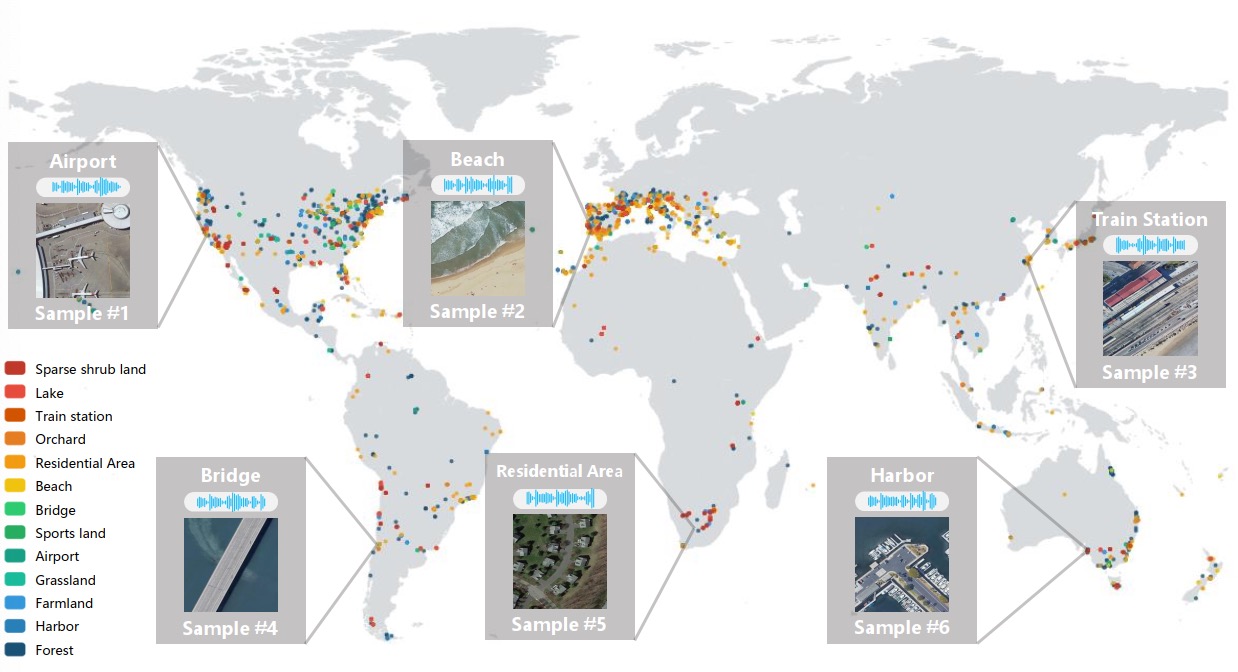 |
AuDio Visual Aerial sceNe reCognition datasEt (ADVANCE) consists of 5,075 geotagged aerial imagesound pairs involving 13 scene classes. The audio data are collected from Freesound, where we remove the audio recordings that are shorter than 2 seconds, and extend those that are between 2 and 10 seconds to longer than 10 seconds by replicating the audio content. From the location information, we can download the updated aerial images from Google Earth. Finally, the paired data are labeled according to the annotations from OpenStreetMap, also using the attached geographic coordinates from the audio recording. Note that, this dataset covers a large variety of scenes from across the world. For more details about this dataset, please refer to our paper. Download this dataset here |
auDIoviSual Crowd cOunting dataset (DISCO)
 |
AuDIoviSual Crowd cOunting dataset (DISCO) consists of 1,935 images and audios from various typical scenes, a total of 170, 270 instances annotated with the head locations. The average, minimum and maximum number of people for each image are 87.99, 1 and 709, respectively. The motivation of building this dataset is that the louder we perceive the ambient sound to be, the more people there are. In a summary, DISCO dataset has three advantages comparing with others: 1) both audio and visual signals are provided; 2) cover different illuminations; and 3) a large variety of scenes are considered. For more details about this dataset, please refer to our paper. Download this dataset here |
Shuttersong Dataset
 |
Shuttersong Dataset contains amounts of pairwise images and songs (lyrics) collected from the Shuttersong application. Shuttersong is a social sharing software, just like Instagram2. However, the shared content contains not only an image, but also a corresponding song clip selected by users, which is for strengthening the expression purpose. A relevant mood can also be appended by users. We collect almost the entire updated data from Shuttersong, which consists of 36,646 pairs of images and song clips. Some optional mood and favorite count information are also included. For more details about this dataset, please refer to our paper. Download this dataset here |